微生物组领域的研究已经产生了大量的数据,从而产生了大量可公开获取的微生物样本,这些样本的准确注释对于跨学科有效利用微生物组数据至关重要。然而,目前主流的微生物数据库存在一个非常大的挑战,即大量的微生物样本缺乏必要的注释,特别是关于收集位置和样本生态位的信息,并且一部分微生物样本可能存在注释错误,这极大地阻碍了环境微生物领域的研究。
2023年8月,华中科技大学生命学院系统生物学与生物信息学系宁康教授团队,以华中科技大学为唯一单位在环境学和生态学领域国际著名期刊《Environmental Science and Ecotechnology》(年综合发文量<50)上发表题为“Refining biome labeling for large-scale microbial community samples: Leveraging neural networks and transfer learning”的研究论文。该研究提出利用神经网络和迁移学习的方法构建预测模型,解决现存微生物数据库中大量样本缺乏生态位标注以及标注不准确的问题,提高众多微生物群落样本的生物群系标签信息的完整性,进而促进跨学科的更准确的知识发现,对环境领域研究具有特别的意义。

在全球最大的微生物组数据库之一的MGnify数据库中,研究人员可获取海量的微生物组样本。为了更好地分析和解读这些数据,精确标记样本信息对于跨学科有效利用微生物组数据而言至关重要。但大量的样本缺乏必要的注释,特别是有关采样地点和样本生物群落信息的注释,这严重制约了环境微生物组研究的进展。
在这项研究中,作者设计了Meta-Sorter,这是一种基于神经网络和迁移学习的工具,用于解开具有不准确生物群落注释的样本的生物群落标签。作者首先基于在2020年1月之前引入MGnify的94,874个样本构建了一个神经网络模型,并表现出很高的稳健性和准确性,然后,作者将这个模型应用于所有被注释为“混合生物群落”的已有样本,结果显示95.41%的微生物样本的群落标签被正确预测。其次,作者引入迁移学习,结合2020年1月之后引入MGnify的微生物样本,重新构建了一个迁移神经网络模型(图1)。作者将此框架应用到16,507个没有详细生物群落注释的样本中,其中96.65%(15,954)的样本被正确分类,从而在很大程度上解决了缺失生物群落标签的问题。最后,作者评估了Meta-Sorter在几个具体的环境案例中的实际应用性能,比如将MGnify中仅标记为“海洋”的样本的实际来源区分为底栖和水柱,并将涉及人-环境相互作用的研究中的样本分类为环境或人类。
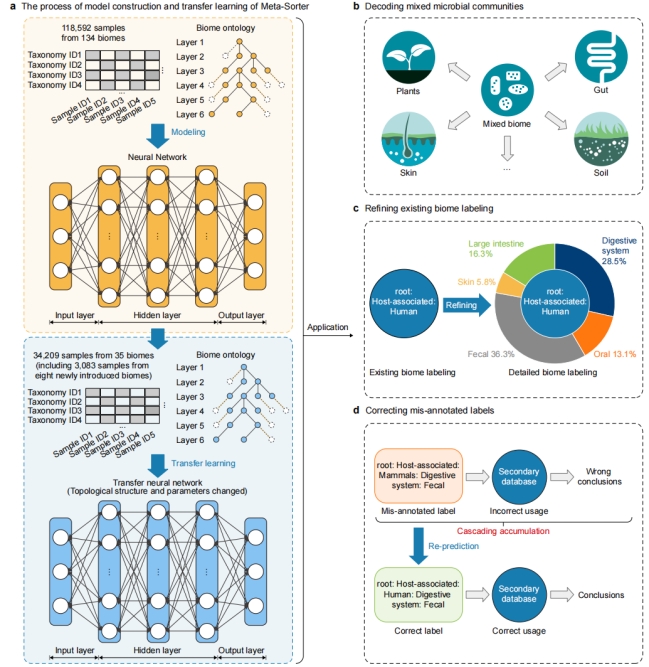
图1. 融合神经网络以及迁移学习的微生物群落标签注释框架
这项研究表明,基于人工智能方法的Meta-Sorter可以提高成千上万个微生物群落样本的生物群系标签信息的完整性,并且Meta-Sorter具有广泛的应用,包括样本分类,来源跟踪,以及从数百万微生物组样本中发现新知识,这极大的促进了环境科学领域的研究。
近年来,华中科技大学生命学院宁康教授团队在生物信息学交叉学科领域进行不断探索,针对微生物组学大数据,发展了一系列人工智能挖掘方法,并成功应用于健康、环境、工业生产等多个转化领域,相关论文发表于PNAS、Gut、Genome Biology、Genome Medicine、Environmental Science and Ecotechnology等生物学、生物信息学领域的国际顶尖期刊。
该研究得到科技部国家重点研发计划(No. 2018YFC0910502),国家自然科学基金(Nos. 32071465, 31871334, 31671374)等的资助。
原文链接:https://www.sciencedirect.com/science/article/pii/S2666498423000698


